초록
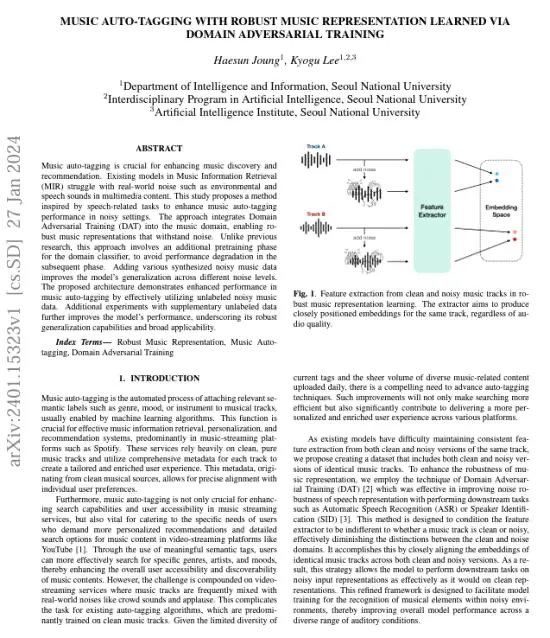
Music auto-tagging is essential for improving music discovery and recommendation. However, existing models in Music Information Retrieval (MIR) face challenges when confronted with real-world noise, such as environmental and speech sounds present in multimedia content. This study presents a novel method inspired by speech-related tasks to enhance music auto-tagging performance in noisy settings. The approach incorporates Domain Adversarial Training (DAT) into the music domain, resulting in robust music representations that can withstand noise interference. Unlike previous research, this approach includes an additional pretraining phase for the domain classifier to prevent performance degradation in subsequent phases. Moreover, the integration of various synthesized noisy music data enhances the model's generalization across different levels of noise. The proposed architecture exhibits superior performance in music auto-tagging by effectively leveraging unlabeled noisy music data. Furthermore, additional experiments with supplementary unlabeled data further enhance the model's performance, highlighting its robust generalization capabilities and broad applicability.
